보통 대시보드를 구성한다고 하면 Elasticsearch 와 Kibana를 이용 하는 경우가 많다. 나도 임성현 선배님이 알려주시지 않았다면 Grafana 를 이용할 생각을 하지 않았을 것 같다. 하지만 Grafana 와InfluxDB 를 사용해보니 정말 쉬운 사용방법, 가벼움, 그리고 어여쁨 모양에 다시 한번 놀라게 되었다
InfluxDB + Grafana 를 이용한 대시보드를 만들기는 아래와 같은 순서로 진행 하였다.
- Deep Learning장비의 CPU, MEMORY, GPU의 사용량, 온도 등 정보 확인
- CPU, MEMORY, GPU의 정보를 Database에 저장
- DataBase 에 저장된 정보를 대시보드(Grafana)로 보여주기
1) CPU, MEMORY, GPU의 사용량, 온도 등 정보 확인
사용하고 있는 Deep Learning 장비가 Ubuntu 이므로 Ubuntu 에서 CPU, MEMORY, GPU 의 사용량과 온도 등의 정보를 확인 하는 방법을 찾다보니 top, htop, glances, free, mpstat, sensors, gpustat, nvidia-smi 등과 같은 많은 것들이 있다는 것을 알게 되었다. (참고:Ubuntu CPU, MEMORY, GPU 상태 체크)
하지만! CPU, MEMORY, GPU 의 정보를 가져오기 위해 추가로 별도의 패키지를 설치하는 등과 같은 일은 없어야 한다. 라는 생각에 Ubuntu 의 기본 패키지, 시스템 파일을 이용하여 CPU, MEMORY, GPU 정보를 가져오는 방법을 찾았다. 이렇게 찾은 것은 top, free, nvidia-smi, 시스템 파일 thermal_zone 이었다
1. top : CPU, MEMORY, PROCESS 등 상태 확인
- Ubuntu 의 대표적인 시스템 모니터링 도구로 기본으로 설치 되어 있다
- CPU, MEMORY, PROCESS 정보들을 한번에 볼 수 있다

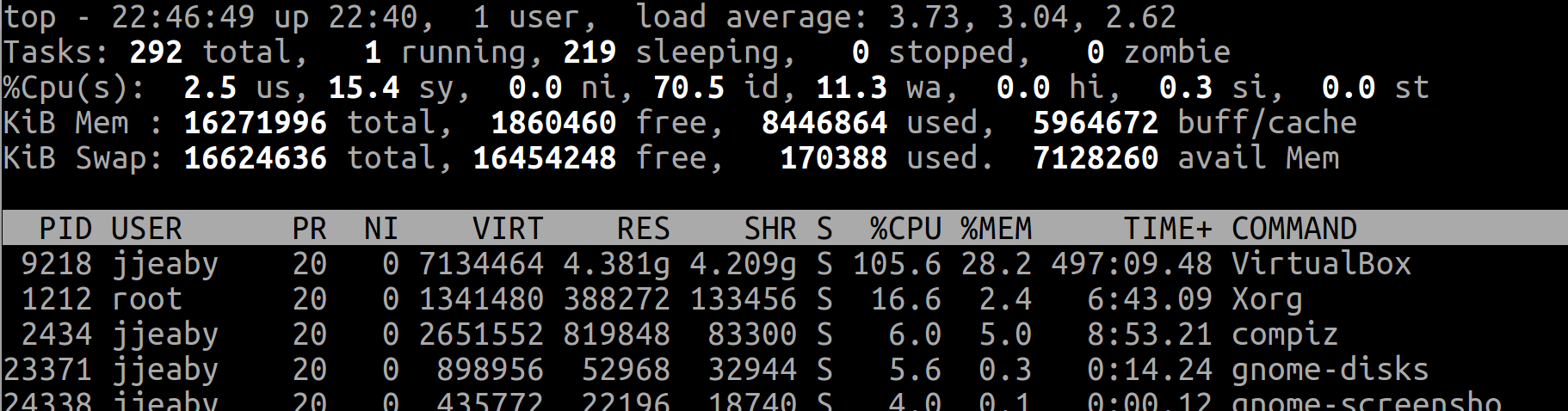
# TIP. CPU 사용량만 보는 Shell 명령어
top -n 1 | grep -i cpu\(s\)| awk '{print $2}'
2. linux 시스템 파일 thermal_zone : cpu 온도
- CPU 온도를 볼 수 있다
- 기본 시스템 파일로 확인 하는 방법으로 별도의 패키지 설치가 필요 없다

/sys/class/themal/thermal_zone*/temp 의 숫자를 1000 으로 나눈 값이 현재 장비의 온도인데, 폴더별로 다른 장비의 온도이다. 이 중 CPU 온도가 저장되는 파일은 같은 폴더에 있는 type 파일을 열고 x86_pkg_temp 문자열이 저장 되어 있는지를 확인 하면 알 수 있다.
3. free : MEMORY 사용량 확인
- Ubuntu 의 대표적인 메모리모니터링 도구로 기본으로 설치 되어 있다
- 물리적 MEMORY, SWAP MEMORY 현황을 보여준다

# TIP. MB 단위로 사용량 보는 Shell 명령어
free -t -m
4. nvidia-smi : NVIDIA GPU 사용량, 온도 등 확인
- GPU 사용량, 온도, 사용 PROCESS 정보들을 한번에 볼 수 있다
- nvidia 드라이버와 함께 설치된다
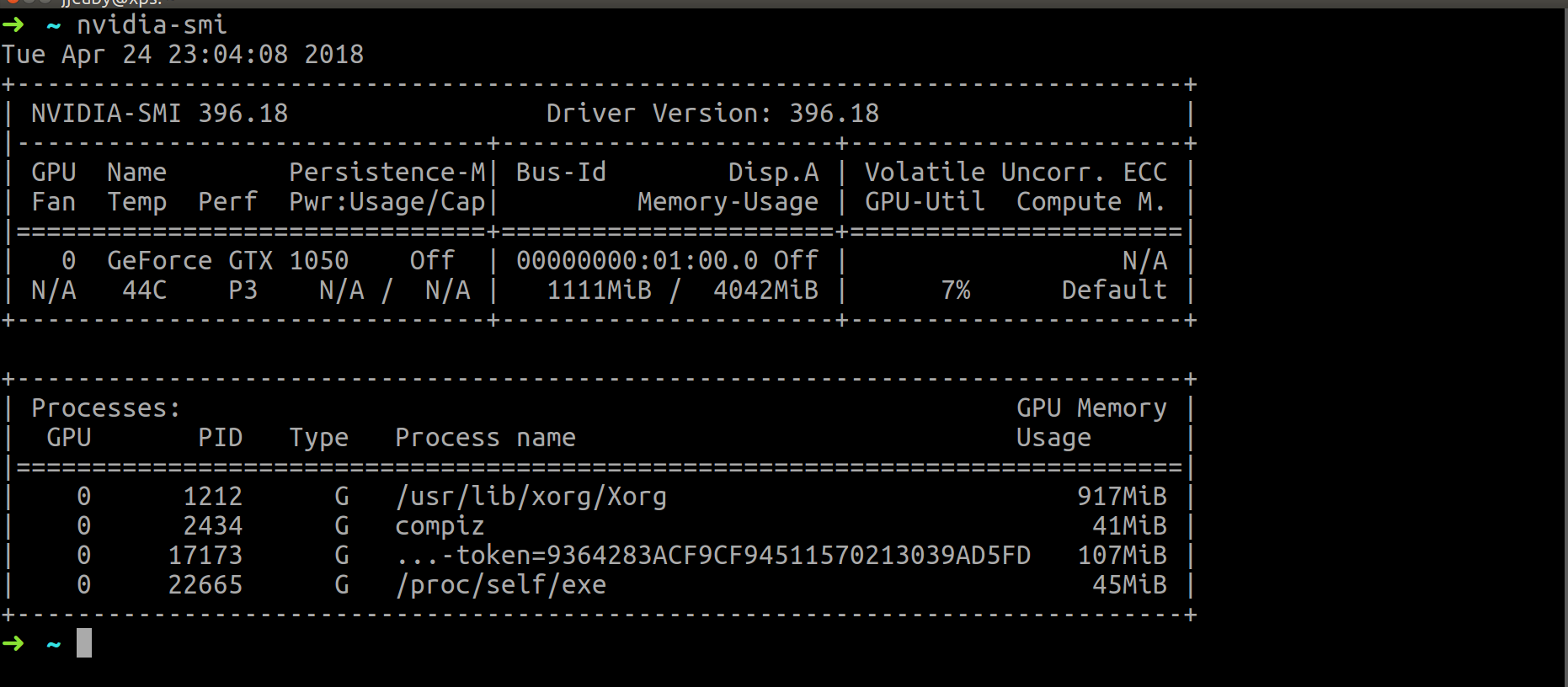
# TIP. CPU 사용량, 정보를 csv 형식으로 출력하는 방법
nvidia-smi --format=csv,noheader,nounits --query-gpu=uuid,name,memory.total,memory.used,memory.free,temperature.gpu | awk -F", " '{gsub(/ /,"_",$2); print "gpu,gpu="NR-1",gpu_name="$2,"memory_total="$3",memory_used="$4",memory_free="$5}'

2) CPU, MEMORY, GPU의 정보를 DataBase에 저장
CPU, MEMORY, GPU 정보를 가져오면 어디에 저장을 할까? FILE 로? MYSQL? POSTGREPSQL? 어디에 할까? 를 찾다보니 Grfana 는 InfluxDB 와 같이 쓰면 좋다는 사실을 알게 되었다.
하지만.... InfluxDB 를 사용해 본 적이 없었기에 InfluxDB 에 대해 공부하고 CPU, MEMORY, GPU 정보를 저장하려고 한다.
[InfluxDB 특징]
InfluxDB는 를 이용하는 오픈 소스 시계열 데이터베이스로 TSM(Time Structured Merge) Tree를 스토리지 엔진으로 사용하는 대표적인 시계열 DataBase 이다.
* 시계열(時系列, time series)은 일정 시간 간격으로 배치된 데이터들의 수열을 말한다.(출처: 위키피디아)
# GOOD
- 압축 알고리즘을 통해 저장 용량 효율도 좋고
- 외부 종속성 없이 설치가 가능한 것도 좋고
- Mongo DB 처럼 스키마가 없는 것도 좋고
- HTTP (S) API 작성 및 쿼리 지원도 좋고
- 동시성, IO 처리 성능이 좋고
- Scale-out 지원도 좋고
- MIT 라이센스도 좋고
- Grafana 연계도 좋고

# NOT GOOD
- Clustering 기능은 0.12.0 버전부터 비용을 지불하고 InfluxData 에서만 지원
- HA 기능은 Influx Relay 오픈소스 프로젝트로 사용할 수 있음
- (https://github.com/influxdata/influxdb-relay : But, 최근 커밋이 2년 전)
- SQL LIKE 검색 불가능( = 검색만 지원 )
- Key Value 구성으로 건수가 커질수록 속도가 느려진다
- WEB UI ADMIN 은 1.1 까지만 지원
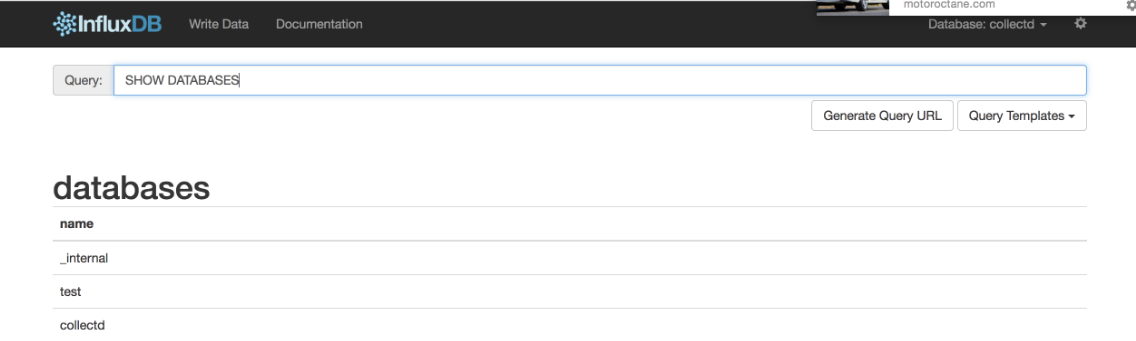
[ InfluxDB WEB UI ADMIN ]
# InfluxDB 주 사용 목적
InfluxDB 는 실시간 데이터 저장, 분석과 작업에 적합합니다.
- 모니터링, 경고, 알림 시스템과 같은 실시간 분석
- 초당 수백만건의 트랜젝션이 발생하는 IoT 정보 저장
# InfluxDB 설치
가능하면 jjeaby/infrafana버전을 Docker 로 설치하는 것을 추천한다.아래의 설명을 보고 원하는 방법으로 InfluxDB 를 설치를 하면 된다.
# Stand Alone 으로 Local 머신에 설치
외부 종속성 없이 설치가 가능한 특징 덕분에 아래 명령어만 입력하면 바로 설치가 완료된다.
wget https://dl.influxdata.com/influxdb/releases/influxdb_1.5.1_amd64.deb
sudo dpkg -i influxdb_1.5.1_amd64.deb
# Docker 로 설치
[ Official Influxdb 설치 ]
1. docker hub 에서 pull 받아서 설치
- port 설명
- 8086 : HTTP API port
docker pull influxdbdocker run -p 8086:8086 -v influxdb:/var/lib/influxdb influxdb
2. kinematic 에서 influx 를 찾아 CREATE 실행,
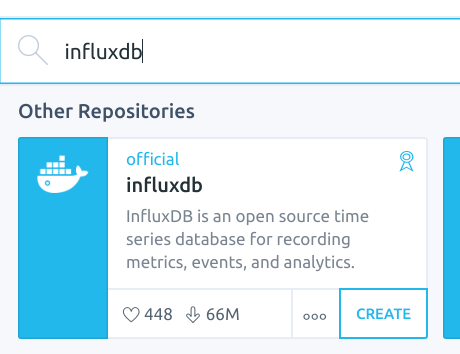
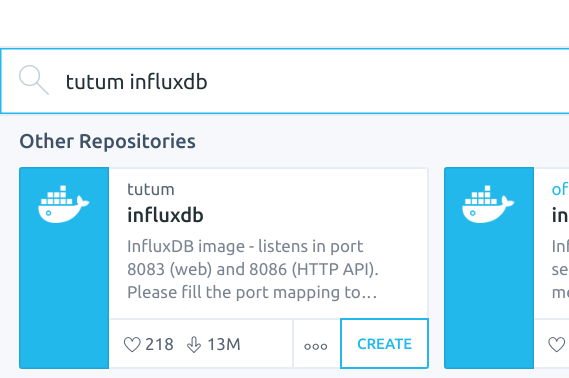
[ tutum influxdb 설치 ]
- influxdb 0.9.6.1 버전이 설치되어 있어 InfluxDB Web UI Admin 사용 가능
- 1.5 까지 버전이 올라가서 0.9.6.1 을 사용하는 것은 권장 하지 않음
1. docker hub 에서 pull 받아서 설치
- port 설명
- 8086 : HTTP API port
- 8083 : WEB ADMIN UI port
docker pull influxdbdocker run -p 8086:8086 -v influxdb:/var/lib/influxdb influxdbdocker pull tutum/influxdbdocker run -d -p 8083:8083 -p 8086:8086 tutum/influxdb:latest
2. kinematic 에서 tumtum influxdb 를 찾아 CREATE 실행
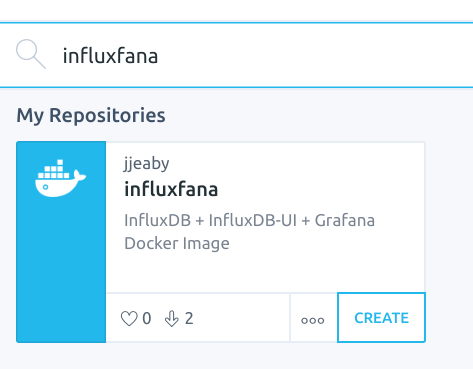
[ jjeaby influxfana 설치 ]
- InfluxDB 1.5, Influxdb-ui 0.1, Grafana 5.0 이 설치된 docker image
- https://github.com/jjeaby/dockerfile/tree/master/infuxdb 참고
1. docker hub 에서 pull 받아서 설치
- port 설명
- 8086 : HTTP API port
- 8083 : Administrator interface port, if it is enabled
- 3000 : Grafana port
- 4000 : Influxdb-ui port
docker pull infuxfanadocker run --name influxDB_WITH_Grafana -d -p 8086:8086 -p 8083:8083 -p 3000:3000 -p 4000:4000 -v /opt/influxDB:/var/lib/influxdb jjeaby:influxfana
2. kinematic 에서 influxfana 를 찾아 CREATE 실행,
infuxfana 에는 InfluxDB, WEB UI ADMIN 이 함께 설치된다.
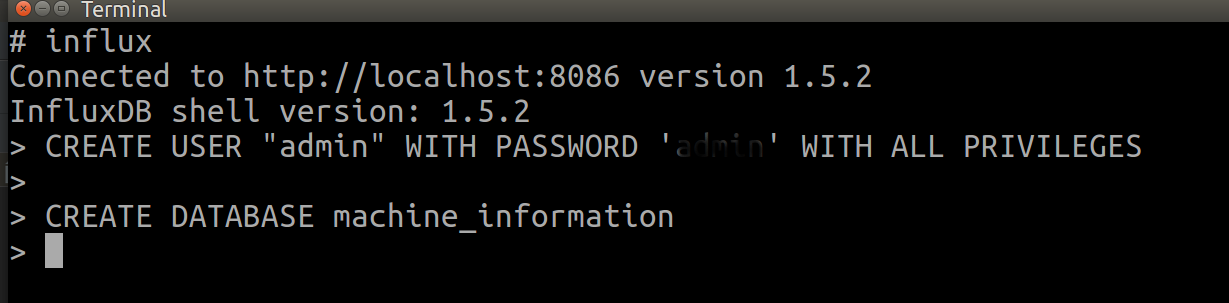
[ InfluxDB Shell ]
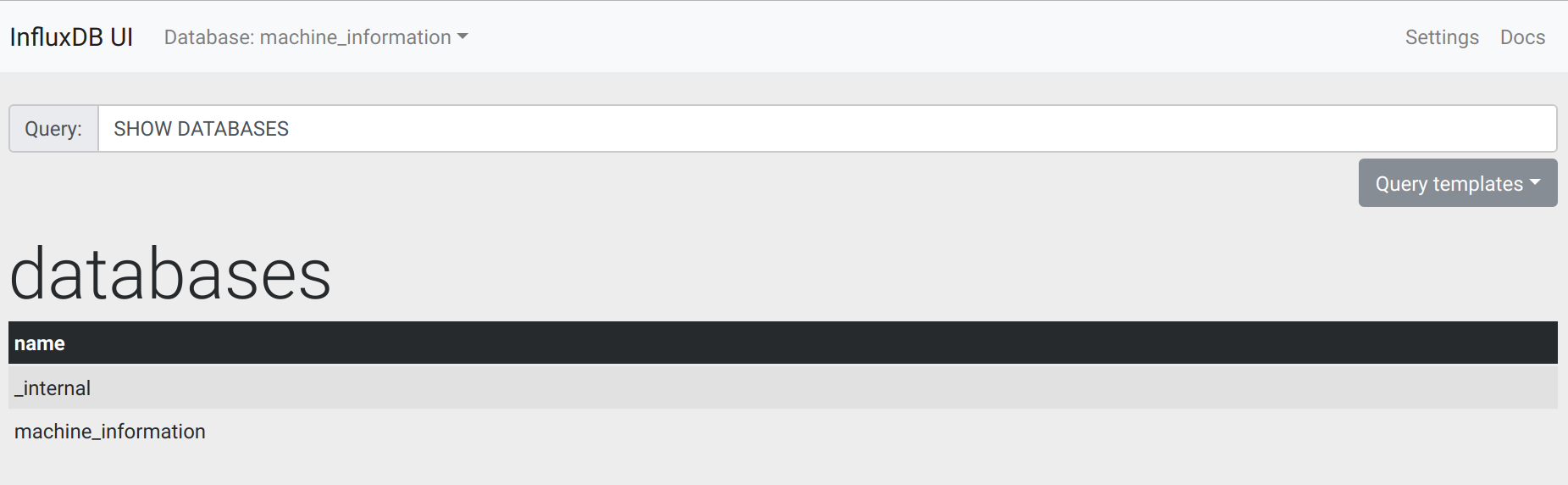
[ Influxdb-ui : WEB ADMIN UI ]
# InfluxDB 계정, DataBase 추가
InfluxDB 접속 계정, Datbase 를 추가하기 위해 influx 명령어로 InfluxDB Shell 로 진입한 뒤 사용할 계정과 DataBase 를 추가한다
추가한 계정은 나중에 InfluxDB 의 인증을 활성화하면 사용하게 된다. 이번 글에서는 인증을 활성화 하지 않으므로 DataBase 만 추가하면 된다.
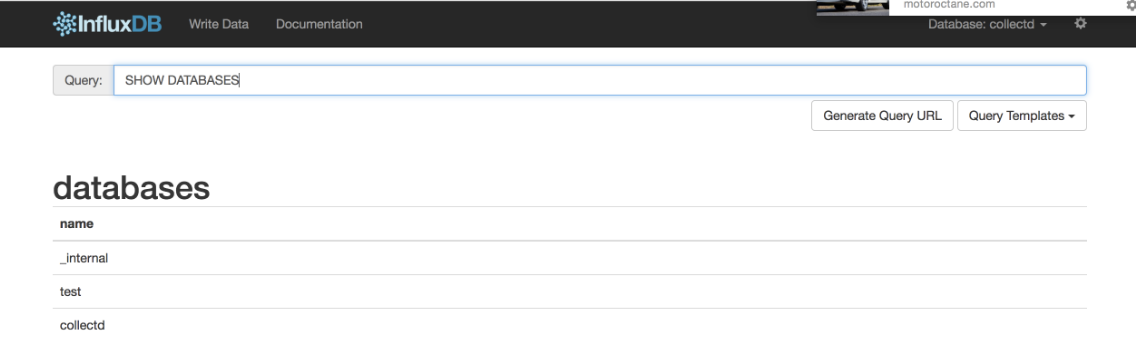
[ InfluxDB Shell ]

[ Influxdb-ui : WEB ADMIN UI ]
InfluxDB 는 Toad, Orange 와 같은 Client 가 없어 ADMIN WEB UI 가 지원되지 않는 것은 꽤나 불편함을 느끼게 해주었다. 그래서, 혹시나 나와 같은 불편함을 가지는 사람이 있지 않을까 하여 찾아보니!! WEB ADMIN UI 를 만들어 놓은 프로젝트를 찾았다. : )
# WEB ADMIN UI
Influxdb-ui 라는 프로젝트로 WEB ADMIN UI 를 제공하는 프로젝트가 개발 되어 있었다. 일단 Fork 를 받고 사용해보니 InfluxDB Shell 의 불편함을 많이 줄일 수 있었다.
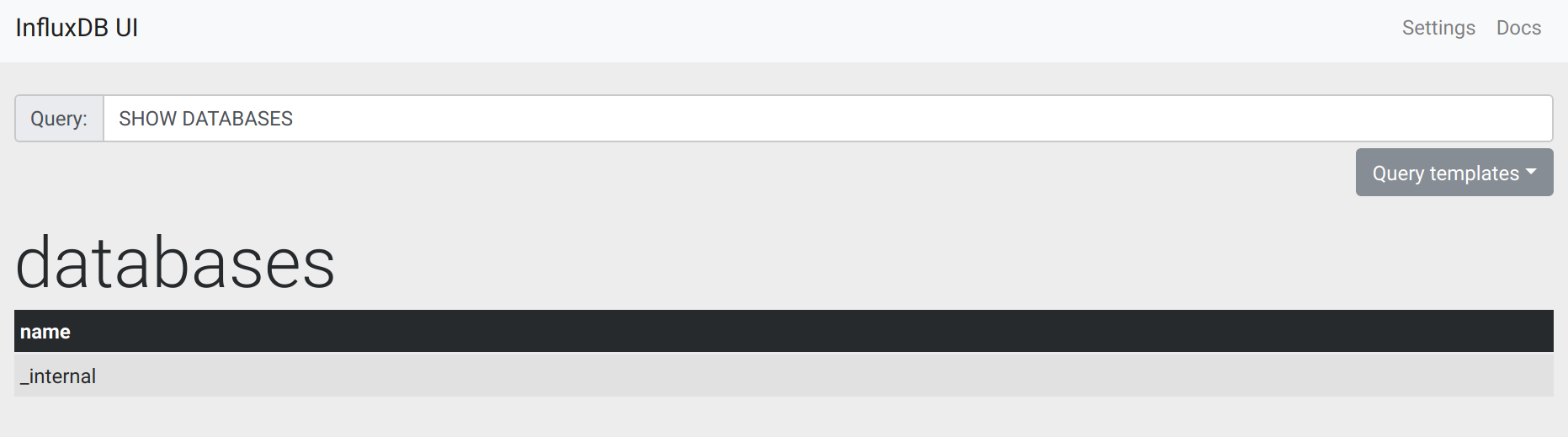
# InfluxDB Query 정리
1) DataBase 생성
CREATE DATABASE jmon
2) DataBase 사용
USE jmon
3) Table 생성,Table 에 Data 입력
# insert 와 함께 table 이 생성된다.
insert servermonitor,server_name=server01 server_ip="11.11.11.11",cpu_usage=1.1,memory_free=4000,memory_used=100,memory_total=4000,gpu_count=1,gpu1_name="Geforce GTX 1050",gpu1_Temperature=35,gpu1_usage=0,gpu1_use=1,gpu1_total=4041,gpu2_name="Geforce GTX 1050",gpu2_Temperature=35,gpu2_usage=0,gpu2_use=1,gpu2_total=4041,gpu3_name="Geforce GTX 1050",gpu3_Temperature=35,gpu3_usage=0,gpu3_use=1,gpu3_total=4041,gpu4_name="Geforce GTX 1050",gpu4_Temperature=35,gpu4_usage=0,gpu4_use=1,gpu4_total=4041
4) Table 목록 조회
show measurements
5) Table 삭제
DROP SERIES FROM servermonitor
# InfluxDB 에 CPU, MEMORY, GPU 정보 저장 방법
python 코드를 이용하여 먼저 이야기한 CPU, MEORY, GPU 의 정보를 가져오는 도구를 이용해 InfluxDB 저장하는 python 모듈을 만들어 봅시다!
python 으로 모듈을 작성한 이유는
- python 코드에 익숙해지기
- InfluxDB 와 연동하기 위한 python 모듈 지원
- pip 를 이용한 쉬운 패키지 구성
이렇게 작성한 코드는 https://github.com/jjeaby/jmon 에서 볼 수 있다.
1.Ubuntu 정보 가져오기(Ubuntu 버전, kernel 버전,컴퓨터 명, IP Address 등)
- uname 을 이용하여 Ubunut, Kernel 등의 정보를 가져온다
- python socket 모듈을 이용하여 IP Address 를 가져온다
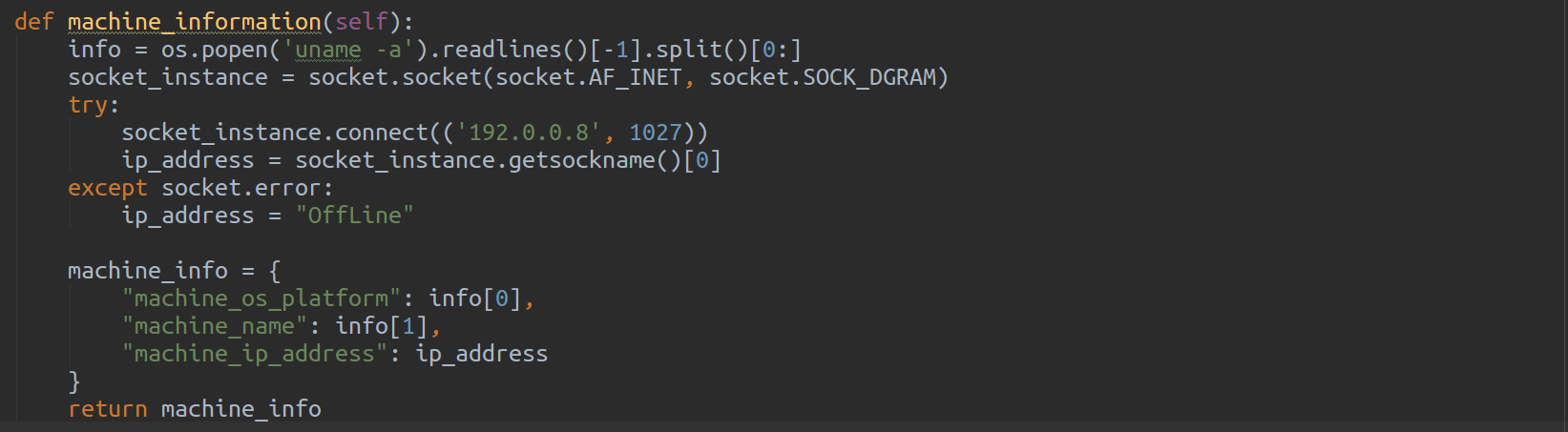
2. CPU 사용량 정보 가져오기
- /proc/stat 시스템 파일을 이용하여 CPU 사용율 정보를 가져온다 .
- /proc/stat 시스템 파일에는 전체 CPU 사용율, CPU Core 별 사용율 정보도 존재한다
- 시스템 파일의 정보를 가져오는 것이 top 을 이용하는 것 보다 빠르고 정확하다
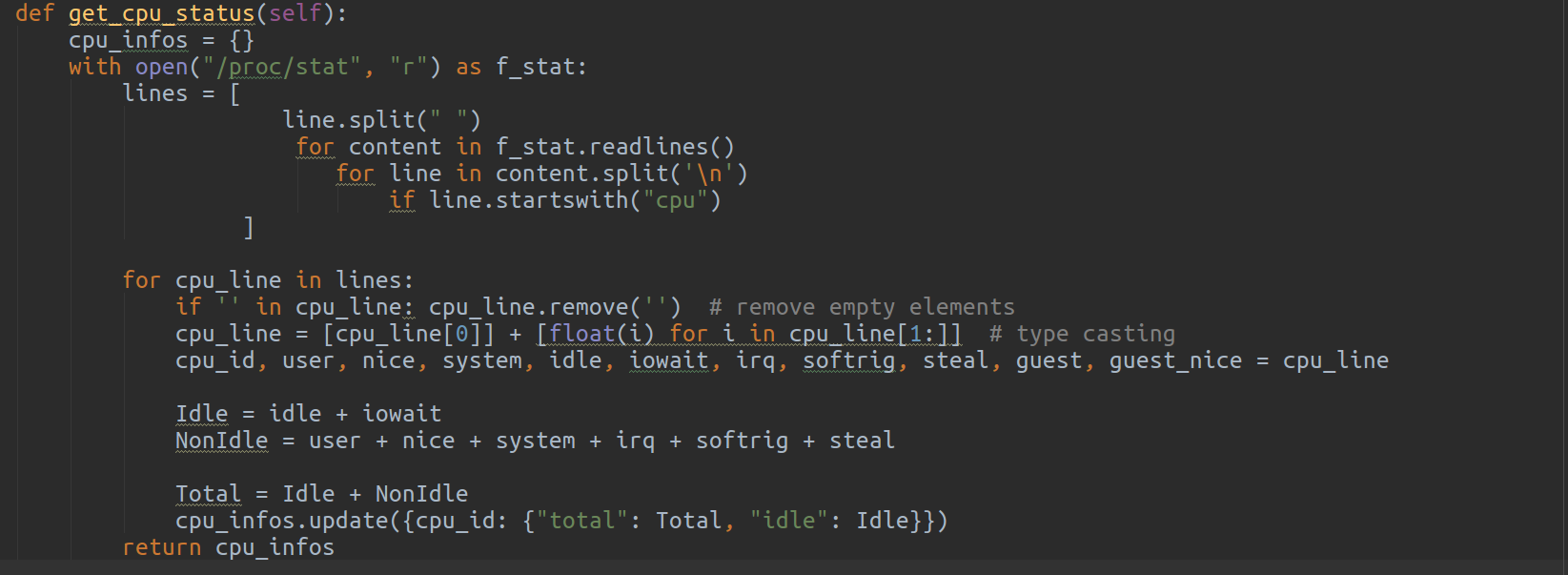
3. CPU 온도 정보 가져오기
- 위에서 설명한 /sys/class/themal/thermal_zone*/temp 시스템 파일을 이용하여 CPU 온도 정보를 가져온다 .
- 별도의 패키지 설치를 하지 않고 빠르고 정확하게 CPU 온도를 가져올 수 있다
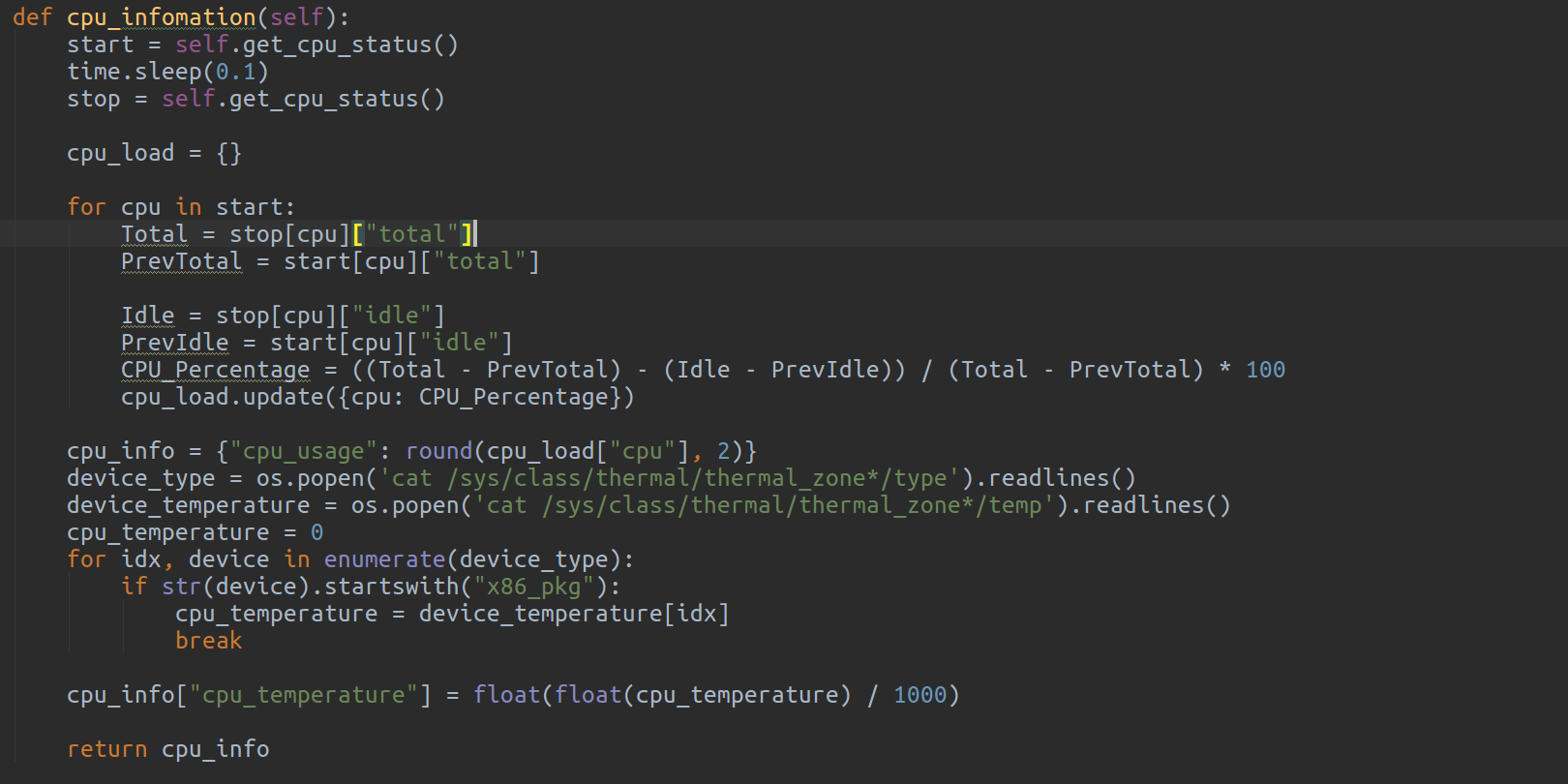
4. MEMORY 사용량 정보 가져오기
- free 명령어를 이용하여 물리적 MEMORY, SWAP MEMORY 전체의 사용량 정보를 가져온다

5. GPU 사용량, 온도 정보 가져오기
- GPU 정보는 nvidia-smi 의 query 기능을 이용하여 csv 형태로 가져올 수 있다
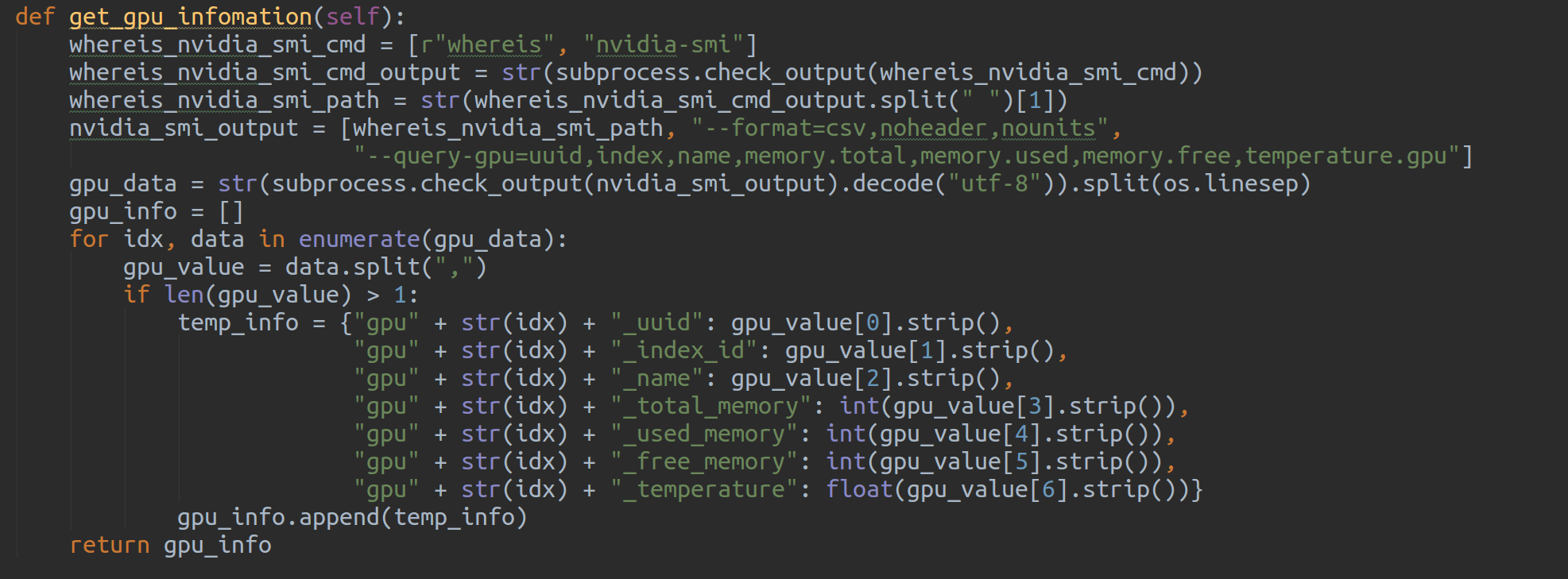
6. InfluxDB 에 저장하기
- python influxdb 모듈을 이용하여 InfluxDB 에 CPU, MEMORY, GPU 사용량 정보를 저장 한다.
- python influxdb 모듈을 사용하기 위해서는 pip 를 이용하여 influxdb 모듈을 설치가 필요하다.
pip install influxdb
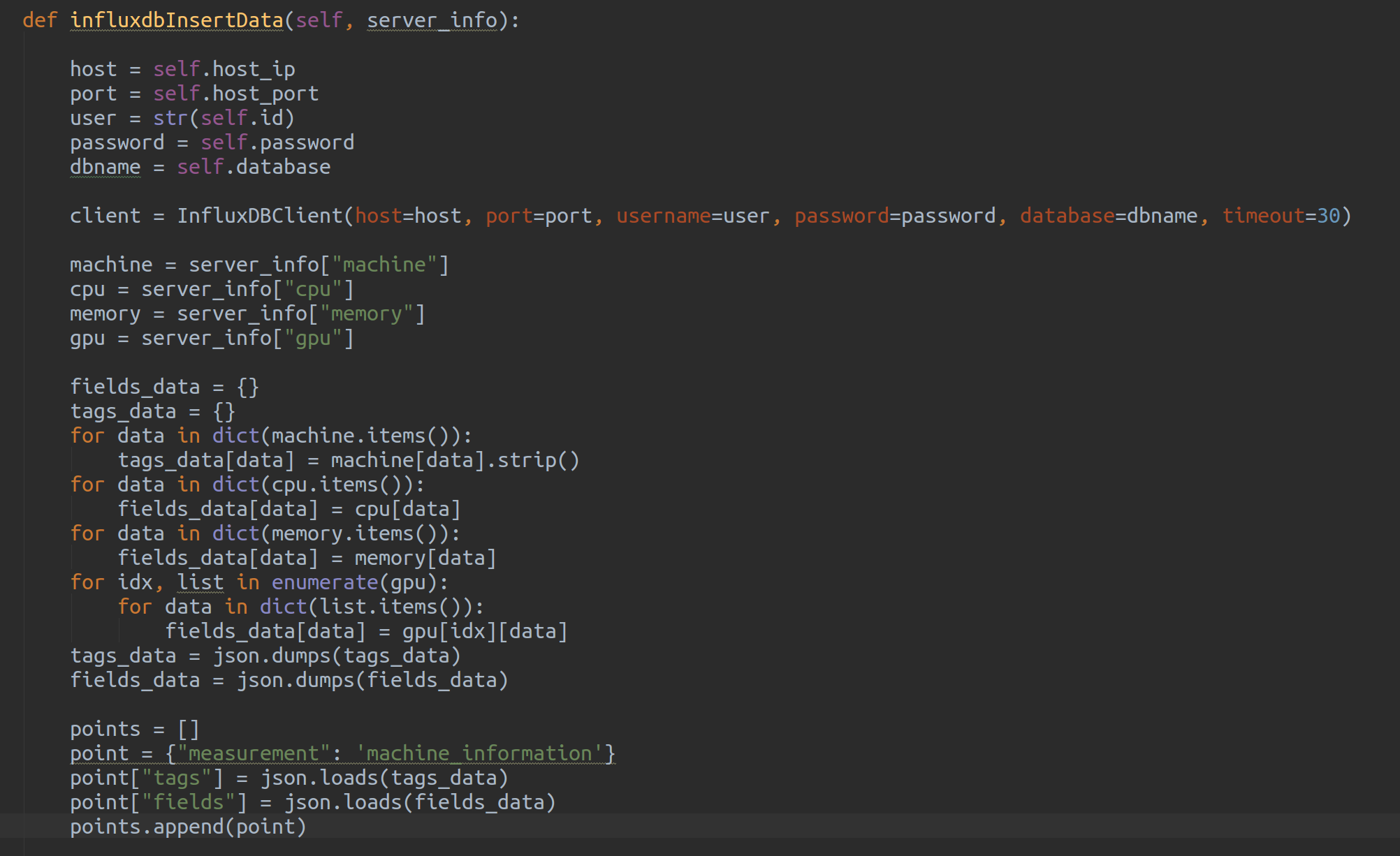
7. pip 패키지로 https://pypi.org 으로 Release
python 모듈을 pypi 에 등록하는 방법은 아래의 순서로 진행하면 된다
1) 패키징을 위한 setup.py 파일 생성
➜ 참고 : https://github.com/jjeaby/jmon/blob/master/setup.py
2) tar archive 파일 생성
➜ python setup.py sdist
3) whl 파일 생성
➜ python setup.py bdist_wheel — universal
4) whl 파일을 pypi 에 업로드
➜ twine upload dist/jmon-0.260-py2.py3-none-any.whl
8. jmon(CPU, MEMORY, GPU 정보 수집 모니터) 실행
- pypi 에 release 한 jmon 을 pip 로 설치하여 실행 할 수 있다
pip install -U jmon

- jmon 사용 방법
# [] 파라미터는 옵션, [] 없는 파라미터는 필수 값임
python -m jmon.machine [-h]
[--ip IP]
[--port PORT]
[--id ID]
[--password PASSWORD]
[--database DATABASE]
[--interval INTERVAL]파라미터 설명 :
-h, --help 파라미터 설명 보여주기(show this help message and exit)
--ip IP InfluxDB 가 설치된 장비의 InfluxDB IP(ip address of InfluxDB http API)
--port PORT InfluxDB 가 설치된 장비의 InfluxDB PORT(port of InfluxDB http API)
--id ID InfluxDB 사용자 ID(InfluxDB user id)
--password PASSWORD InfluxDB 사용자 PASSWORD(InfluxDB user password)
--database DATABASE 정보를 저장할 InfluxDB의 Database(InfluxDB Database Name)
--interval INTERVAL CPU, MEMORY, GPU 정보를 가져올 주기(monitoring interval second)
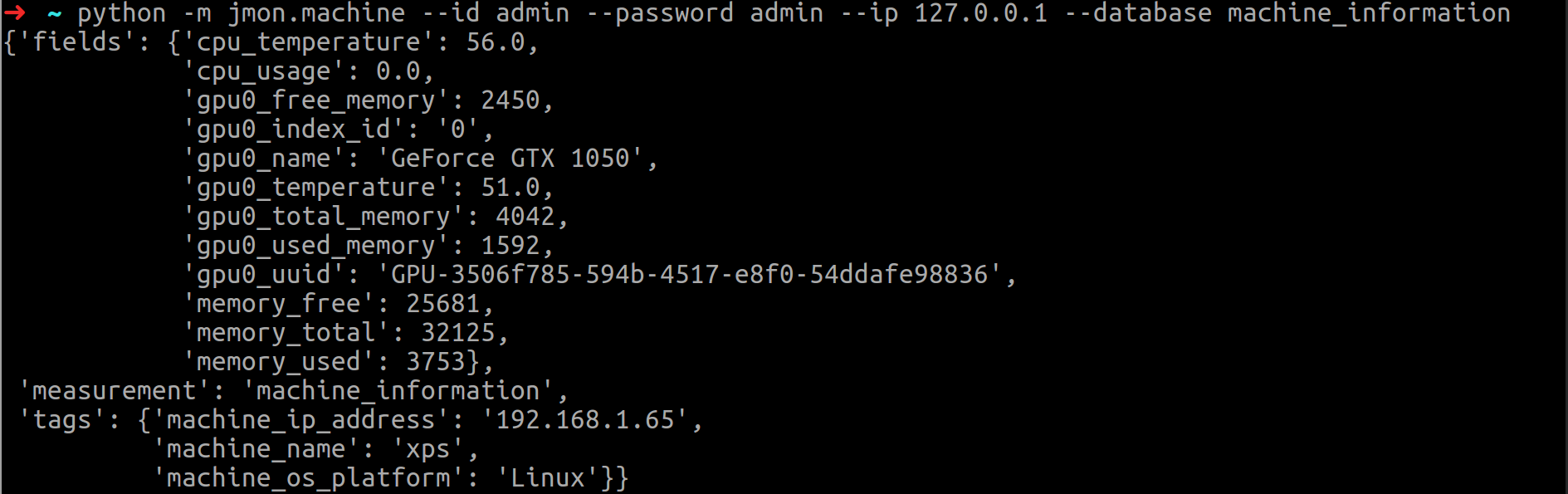
9. jmon(CPU, MEMORY, GPU 정보 수집 모니터) 저장 데이터 확인
- InfluxDB 에 접속하여 정상적으로 jmon 이 동작 되고 있는지를 확인 한다

10. InfluxDB 의 정보를 대시보드(Grafana)로 보여주기
Grafana 는 Graphite, influxDB, MYSQL, OpenTSDM 등을 백엔드로 사용하는 대시보드 도구입니다. 정말 많은 대시보드 도구들 중 많은 관심을 받고 있다.
Grafana 를 처음 보면 Kibana 를 사용와 뭐가 다른지, 왜 서야 하는지 궁금함이 드는 것은 정상입니다. Grafana는 Elasticsearch 의 대시보드 Kibana 에 영향을 받아 시작된 Open Source 프로젝트이기 때문입니다. Grafana 는 데이터 질의를 통한 검색 기능을 제외한 대시보드, 시각화 기능은 Kibana 보다 좋습니다.
# GOOD
- Open Source 여서 좋고
- 대시보드가 이뻐서 좋고
- 대시보드 공유하기도 좋고
- 다양한 Plug-in 이 있어서 좋고
- 다양한 DataBase 를 지원해서 좋고
Grafana 설치 방법
InfluxDB 설치 방법을 이야기 할때 Docker 로 jjeaby/influxfana 를 설치하였다면 이미 Grafana 가 설치 되어 있으므로 Grafana 대시보드 구성으로 넘어가면 된다. (Grafana 설치 : http://docs.grafana.org/installation/debian/ 참고)
1) Stand Alone 으로 Local 머신에 설치
wget https://s3-us-west-2.amazonaws.com/grafana-releases/release/grafana_5.0.4_amd64.debsudo apt-get install -y adduser libfontconfig
sudo dpkg -i grafana_5.0.4_amd64.deb
sudo /bin/systemctl daemon-reload
sudo /bin/systemctl enable grafana-server
2) Official Grafana Docker 로 설치
- Grafana 5.0.4 가 설치된 docker image
- https://hub.docker.com/r/grafana/grafana 참고
2-1) docker hub 에서 pull 받아서 설치
- port 설명
- 3000 : Grafana port
docker pull grafana/grafanadocker run -d -p 3000:3000 --name=grafana --volumes-from grafana-storage grafana/grafana
2-2) kinematic 에서 influxfana 를 찾아 CREATE 실행,
Grafana 대시보드 구성
구성 방법은 아주 친절하게도 Grafana 에 처음 로그인하면 아이콘으로 알려준다.
1) Grafana 접속
- 설치하면 기본 계정은 admin // admin 으로 설정 되어 있다.
- 로그인 후 나타나는 그림의 순서대로 대시보드를 만들면 된다.

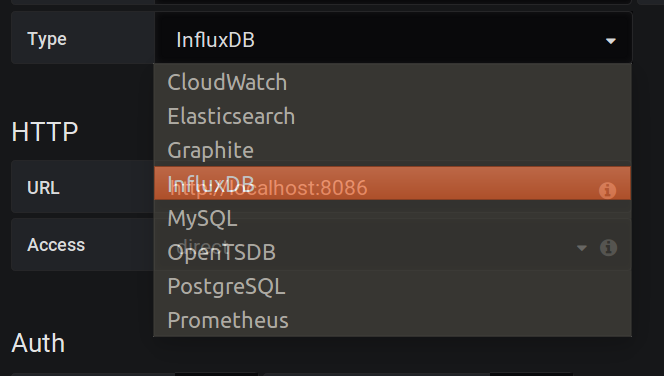
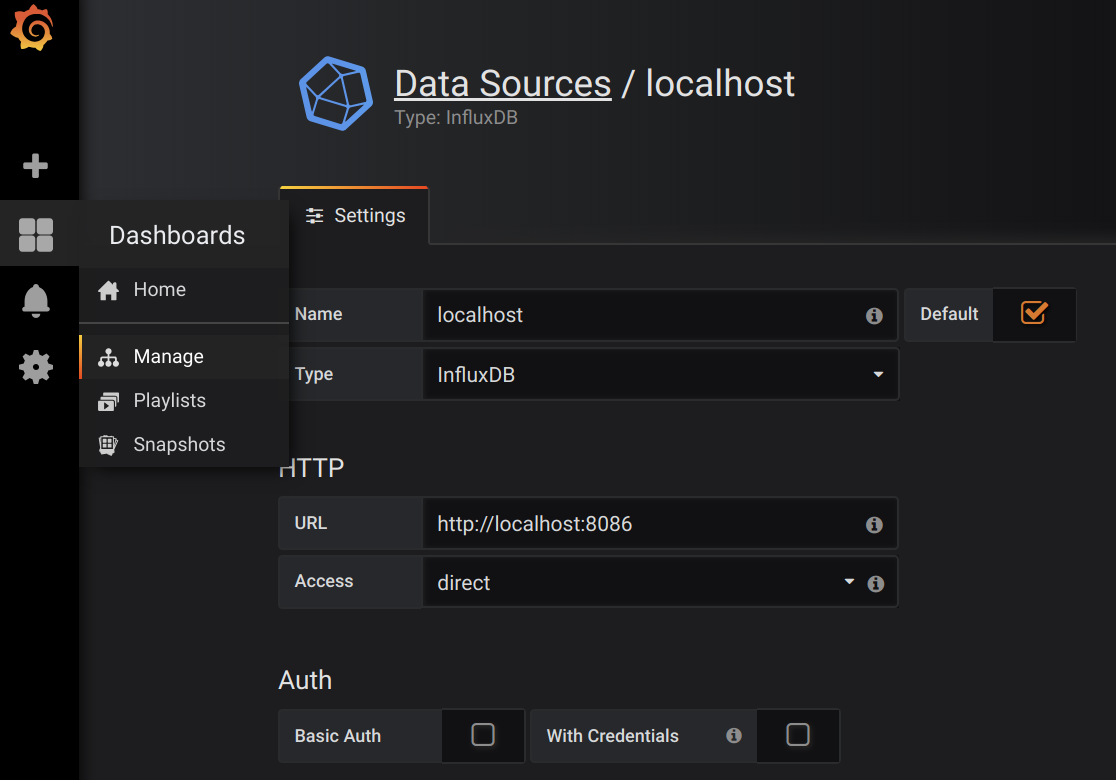
2) Data Source 추가 하기
- Add data source 아이콘을 클릭하면

- Data Source 추가 화면에 아래와 같은 정보를 입력하고 Save & Test 버튼을 클릭하면 된다.

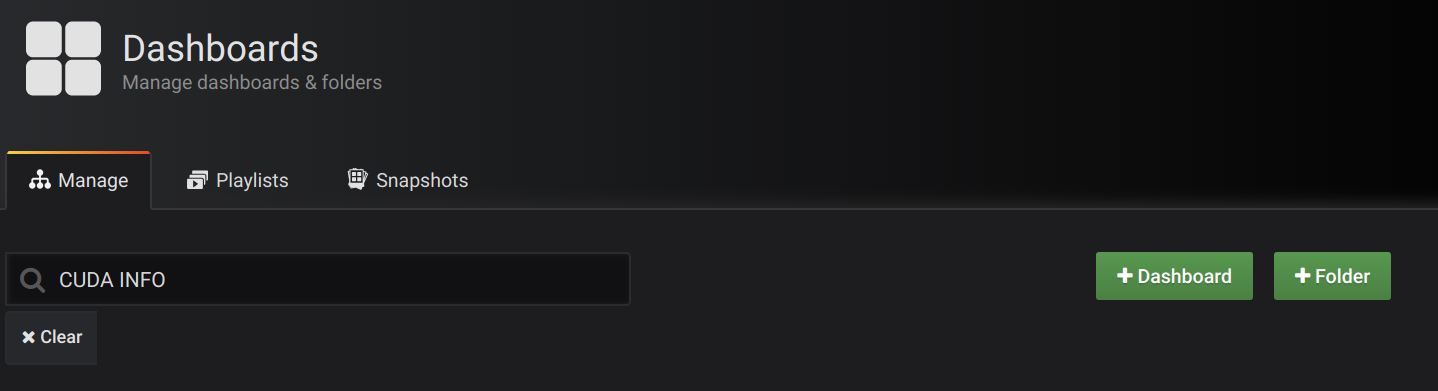
3) Dashboard 추가 하기
- Dashboards > Manage 메뉴로 이동하여 Dashboard 이름을 입력하고 Dashboard 추가 버튼을 눌러 저장 한다
- Graph 를 클릭하여 새로운 Graph Dashboard 를 추가한다
- 추가된 Panel 을 클릭하고 ‘E’ 를 누르거나, Panel Title 을 클릭하여 Edit 모드로 진입하면 Panel 에 보여줄 값을 설정 할 수 있다
- Panel Edit 화면에서 Query 입력기의 햄버거 메뉴를 클릭하여 Toggle Edit Mode 로 진입하여 Query 를 입력하면 그래프가 나타난다
** Query 입력은 아래 Query 들을 참고 하세요
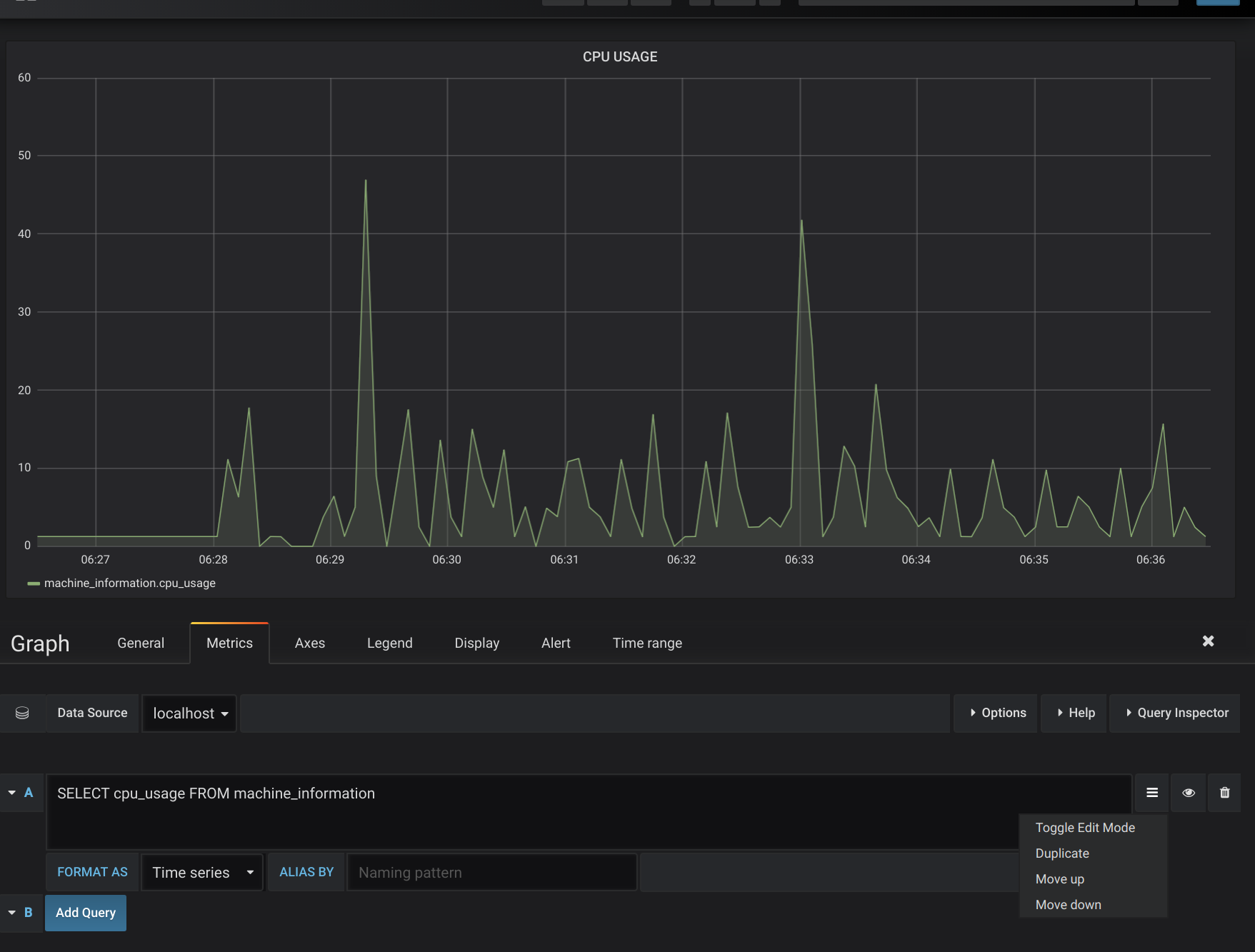
# CPU 사용량, 온도
SELECT cpu_usage, CPU_temperature FROM machine_information GROUP BY machine_name# MEMORY 사용랴야
SELECT (memory_free / memory_total) FROM machine_information GROUP BY machine_name$ GPU 사용량, 온도
SELECT (gpu0_used_memory / gpu0_total_memory), gpu0_temperature FROM machine_information GROUP BY machine_name
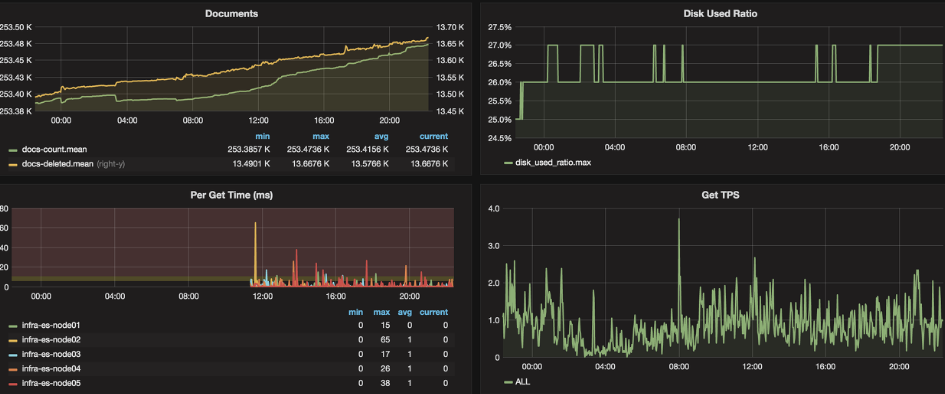
** Panel 추가를 반복하여 원하는 모양의 Panel 추가하면 아래와 같은 Dashboard 가 완성 된다.
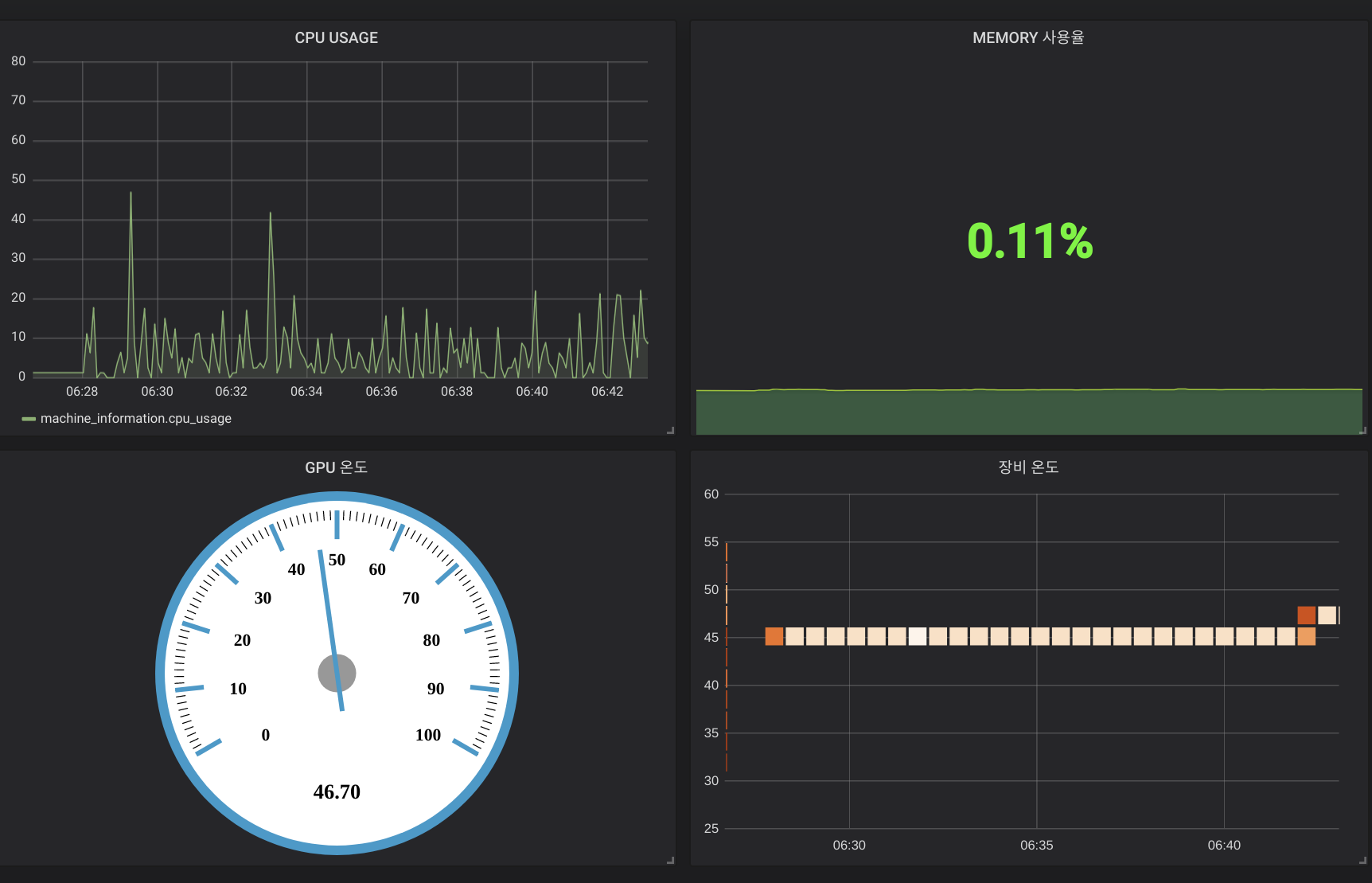
InfluxDB + Grafana + Python = Machine Monitor
InfluxDB + Grafana + Python 을 이용한 CPU, MEMORY, GPU 정보를 모니터링 하는 대시 보드를 만들어 보았다. Open Source 로 유명한 influxDB, Grafna 를 사용하였고 Docker, Pypi 를 이용하여
- InfluxDB + InfluxDB-ui + Grafana docker hub 이미지 만들기
- pip 설치가 가능한 jmon 패키징 하기
를 통해 Deep Learning Machine Monitoring 대시보드를 쉽게 만들 수 있도록 구성 하였다.
물론! 짬짬히 만들었기 때문에 문제점들은 많겠지만, 간단하게 써보고 싶은 분들이 있을까 싶어서 사용방법을 3 단계로 정리해 보았다.
1) influxfana Docker 이미지 받기
docker pull influxfana
docker run — name influxDB_WITH_Grafana -d -p 8086:8086 -p 8083:8083 -p 3000:3000 -p 4000:4000 -v /opt/influxDB:/var/lib/influxdb jjeaby:influxfana2) jmon 설치
pip instsall jmon
pytho -m jmon.machin --ip [InfluxDB 가 설치왼 장비 IP]--port [InfluxDB 가 설치왼 장비 Port] --database [InfluxDB DataBase 이름]3) Grafana Dashboard 구성
- 1) 에서 구성한 InfluxDB 를 Data Source 추가
- 아래 쿼리를 참고하여 새로운 DashBoard 추가
# CPU 사용량, 온도
SELECT cpu_usage, CPU_temperature FROM machine_information GROUP BY machine_name# MEMORY 사용랴야
SELECT (memory_free / memory_total) FROM machine_information GROUP BY machine_name$ GPU 사용량, 온도
SELECT (gpu0_used_memory / gpu0_total_memory), gpu0_temperature FROM machine_information GROUP BY machine_name'개발' 카테고리의 다른 글
| Sentence Tokenized English (0) | 2020.05.29 |
|---|---|
| Using RM Commands Safely in Ubuntu (0) | 2020.05.29 |
| Ubuntu Device Status Check : CPU, MEMORY, PROCESS (0) | 2020.05.29 |
| Ubuntu 부팅시 발생하는 grub rescue 메세지 (0) | 2020.05.28 |
| MAC(OSX)에서 PNG → JPG 일괄 변환하기 (0) | 2020.05.28 |



